LivePortrait, AnimateDiff, Stable Video Diffusion을 활용한 표정 변화,
머리카락·옷 움직임이 포함된 동영상 생성 서비스 개발
개요 및 도구 비교
LivePortrait
얼굴 표정 애니메이션 전문
- ✓ 눈 깜빡임, 입술·눈썹 움직임
- ✓ 69백만 프레임 학습 모델
- ✓ 빠른 처리 속도 (12.8ms/frame)
- ✗ 머리카락·옷 움직임 제한적
AnimateDiff
텍스트 기반 비디오 생성
- ✓ 프롬프트 트래블로 표정 변화
- ✓ Motion LoRA로 카메라 움직임
- ✓ ControlNet 지원
- ✓ 다양한 모션 효과
Stable Video Diffusion
이미지→비디오 변환
- ✓ 고품질 이미지 애니메이션
- ✓ 4초~수십초 영상 생성
- ✓ SDXL 지원 (1024×1024)
- ⚠ 높은 VRAM 요구사항 (40GB)
권장 조합 전략
LivePortrait로 얼굴 표정 애니메이션을 생성하고, AnimateDiff로 배경·전체적인 움직임을 추가하여 최종 영상을 완성하는 하이브리드 접근 방식을 권장합니다. 머리카락·옷 움직임이 중요한 경우 Stable Video Diffusion을 추가로 활용할 수 있습니다
단계별 설치 가이드
1CUDA 12.7 설치
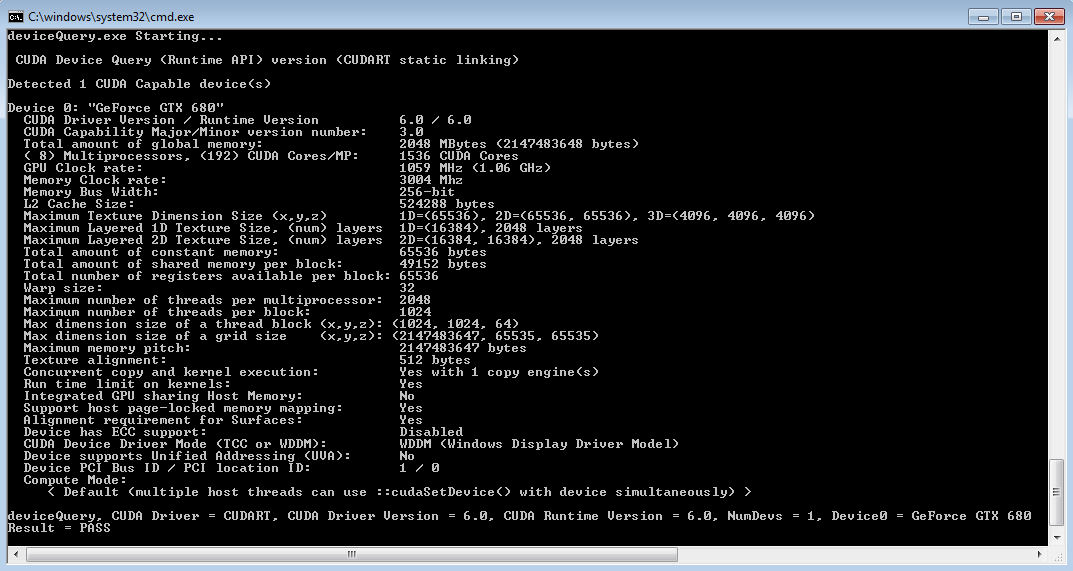
NVIDIA CUDA Toolkit 다운로드 에서 Windows x86_64용 CUDA 12.7을 다운로드합니다.
# GPU 확인
nvidia-smi주의: Windows에서 CUDA 12.4, 12.6 등 일부 최신 버전은 예기치 못한 문제가 발생할 수 있으므로, 안정성을 위해 CUDA 12.6 사용을 권장합니다. [GitHub]
2Python 3.10 및 PyTorch 설치
# Conda 환경 생성
conda create -n ai_animation python=3.10conda activate ai_animation# PyTorch 설치 (CUDA 12.6 기준)
pip3 install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu126CUDA 12.7 사용자는 nightly 빌드를 사용하면 됩니다. PyTorch는 CUDA 하위 호환성을 지원합니다. [discuss.pytorch.org]
# 설치 확인
python -c "import torch; print(f'CUDA available: {torch.cuda.is_available()}')"3ComfyUI 설치
# ComfyUI 클론 및 설치
git clone https://github.com/comfyanonymous/ComfyUI.gitcd ComfyUIpip install -r requirements.txt# ComfyUI 실행
python main.py --listenComfyUI가 설치되면 브라우저에서 http://localhost:8188로 접속하여 웹 인터페이스를 확인할 수 있습니다. [stable-diffusion-art.com]
4LivePortrait 설치
방법 1: Windows 원클릭 설치 (권장)
# HuggingFace에서 다운로드
LivePortrait-Windows-v20240829.zip# 압축 해제 후 실행
run_windows.bat방법 2: 수동 설치
ComfyUI용 LivePortrait 노드 설치
# ComfyUI 커스텀 노드 설치
cd ComfyUI/custom_nodes/git clone https://github.com/kijai/ComfyUI-LivePortraitKJ.gitpip install insightface필요한 모델 파일들은 HuggingFace에서 자동으로 다운로드되며, ComfyUI/models/liveportrait 폴더에 저장됩니다. [GitHub]
5AnimateDiff 설치
# AUTOMATIC1111 WebUI 확장으로 설치
Extensions → Install from URLhttps://github.com/continue-revolution/sd-webui-animatediff주요 기능
- • 프롬프트 트래블: 프레임별 다른 프롬프트로 표정·동작 변화 생성
- • Motion LoRA: Pan, Zoom 등 카메라 움직임 추가
- • ControlNet 지원: OpenPose, Canny 등으로 정밀한 움직임 제어
- • 이미지→비디오: 시작/끝 이미지 지정으로 구성 제어
6Stable Video Diffusion 설치
# ComfyUI 커스텀 노드 설치
cd ComfyUI/custom_nodes/git clone https://github.com/thecooltechguy/ComfyUI-Stable-Video-Diffusionpython install.py높은 시스템 요구사항
- • 최소 40GB VRAM 필요 (원본 모델 기준)
- • RTX 4090 (24GB) 사용 시 해상도/배치 크기 조정 필요
- • 대안: 경량화된 XT 버전 사용 권장
필요한 모델 파일 (ComfyUI/models/svd/)
# 기본 모델
svd.safetensorssvd_image_decoder.safetensors# 확장 모델 (더 긴 영상)
svd_xt.safetensorssvd_xt_image_decoder.safetensors모델 파일은 HuggingFace Stability AI에서 다운로드할 수 있습니다. [GitHub]

AI 이미지 애니메이션 서비스 구현
1. 메인 서비스 클래스 (ai_animation_service.py)
import os
import sys
import torch
import cv2
import numpy as np
from pathlib import Path
from typing import Optional, Dict, Any, List
import logging
from dataclasses import dataclass
from datetime import datetime
# LivePortrait 관련 임포트
sys.path.append(os.path.join(os.path.dirname(__file__), 'LivePortrait', 'src'))
from liveportrait.utils.cropper import Cropper
from liveportrait.live_portrait_pipeline import LivePortraitPipeline
# AnimateDiff/ComfyUI 관련 임포트
import requests
import json
import websocket
import uuid
from PIL import Image
@dataclass
class AnimationConfig:
"""애니메이션 설정 클래스"""
input_image_path: str
output_video_path: str
animation_type: str = "liveportrait" # liveportrait, animatediff, svd
duration: float = 4.0 # 초
fps: int = 25
resolution: tuple = (512, 512)
motion_scale: float = 1.0
enable_face_animation: bool = True
enable_background_motion: bool = False
prompt: Optional[str] = None # AnimateDiff용
negative_prompt: Optional[str] = None
class AIAnimationService:
"""AI 이미지 애니메이션 통합 서비스"""
def __init__(self, config_path: Optional[str] = None):
self.logger = self._setup_logger()
self.device = "cuda" if torch.cuda.is_available() else "cpu"
self.logger.info(f"Using device: {self.device}")
# 각 모델 파이프라인 초기화
self.liveportrait_pipeline = None
self.comfyui_client = None
# 모델 경로 설정
self.models_dir = Path("models")
self.temp_dir = Path("temp")
self.temp_dir.mkdir(exist_ok=True)
self._initialize_models()
def _setup_logger(self) -> logging.Logger:
"""로거 설정"""
logger = logging.getLogger("AIAnimationService")
logger.setLevel(logging.INFO)
if not logger.handlers:
handler = logging.StreamHandler()
formatter = logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
handler.setFormatter(formatter)
logger.addHandler(handler)
return logger
def _initialize_models(self):
"""모델 초기화"""
try:
self._initialize_liveportrait()
self._initialize_comfyui_client()
self.logger.info("All models initialized successfully")
except Exception as e:
self.logger.error(f"Model initialization failed: {e}")
def _initialize_liveportrait(self):
"""LivePortrait 모델 초기화"""
try:
config_path = "LivePortrait/configs/liveportrait.yaml"
if os.path.exists(config_path):
self.liveportrait_pipeline = LivePortraitPipeline(
config_path=config_path,
device=self.device
)
self.logger.info("LivePortrait pipeline initialized")
else:
self.logger.warning("LivePortrait config not found")
except Exception as e:
self.logger.error(f"LivePortrait initialization failed: {e}")
def _initialize_comfyui_client(self):
"""ComfyUI 클라이언트 초기화"""
try:
self.comfyui_url = "http://localhost:8188"
# ComfyUI 서버 연결 테스트
response = requests.get(f"{self.comfyui_url}/system_stats")
if response.status_code == 200:
self.comfyui_client = ComfyUIClient(self.comfyui_url)
self.logger.info("ComfyUI client initialized")
else:
self.logger.warning("ComfyUI server not accessible")
except Exception as e:
self.logger.warning(f"ComfyUI initialization failed: {e}")
def create_animation(self, config: AnimationConfig) -> Dict[str, Any]:
"""메인 애니메이션 생성 함수"""
self.logger.info(f"Starting animation creation: {config.animation_type}")
try:
if config.animation_type == "liveportrait":
return self._create_liveportrait_animation(config)
elif config.animation_type == "animatediff":
return self._create_animatediff_animation(config)
elif config.animation_type == "svd":
return self._create_svd_animation(config)
elif config.animation_type == "hybrid":
return self._create_hybrid_animation(config)
else:
raise ValueError(f"Unsupported animation type: {config.animation_type}")
except Exception as e:
self.logger.error(f"Animation creation failed: {e}")
return {"success": False, "error": str(e)}
def _create_liveportrait_animation(self, config: AnimationConfig) -> Dict[str, Any]:
"""LivePortrait를 사용한 얼굴 애니메이션 생성"""
if not self.liveportrait_pipeline:
return {"success": False, "error": "LivePortrait not initialized"}
try:
# 입력 이미지 로드
source_image = cv2.imread(config.input_image_path)
if source_image is None:
raise ValueError("Could not load input image")
# 얼굴 크롭 및 전처리
cropper = Cropper()
crop_info = cropper.crop_image(source_image)
# 애니메이션 생성 (간단한 눈 깜빡임 효과)
frames = []
total_frames = int(config.duration * config.fps)
for frame_idx in range(total_frames):
# 간단한 눈 깜빡임 시뮬레이션
blink_factor = self._calculate_blink_factor(frame_idx, total_frames)
# LivePortrait 파이프라인 실행
animated_frame = self.liveportrait_pipeline.inference(
source_image=crop_info['crop_image'],
driving_motion=self._generate_driving_motion(blink_factor),
motion_scale=config.motion_scale
)
frames.append(animated_frame)
# 비디오 저장
self._save_video(frames, config.output_video_path, config.fps)
return {
"success": True,
"output_path": config.output_video_path,
"duration": config.duration,
"fps": config.fps,
"total_frames": len(frames)
}
except Exception as e:
self.logger.error(f"LivePortrait animation failed: {e}")
return {"success": False, "error": str(e)}
def _create_animatediff_animation(self, config: AnimationConfig) -> Dict[str, Any]:
"""AnimateDiff를 사용한 애니메이션 생성"""
if not self.comfyui_client:
return {"success": False, "error": "ComfyUI not available"}
try:
# AnimateDiff 워크플로우 생성
workflow = self._create_animatediff_workflow(config)
# ComfyUI를 통해 실행
result = self.comfyui_client.queue_prompt(workflow)
if result["success"]:
return {
"success": True,
"output_path": config.output_video_path,
"prompt_id": result["prompt_id"]
}
else:
return {"success": False, "error": result["error"]}
except Exception as e:
self.logger.error(f"AnimateDiff animation failed: {e}")
return {"success": False, "error": str(e)}
def _create_svd_animation(self, config: AnimationConfig) -> Dict[str, Any]:
"""Stable Video Diffusion을 사용한 애니메이션 생성"""
if not self.comfyui_client:
return {"success": False, "error": "ComfyUI not available"}
try:
# SVD 워크플로우 생성
workflow = self._create_svd_workflow(config)
# ComfyUI를 통해 실행
result = self.comfyui_client.queue_prompt(workflow)
return result
except Exception as e:
self.logger.error(f"SVD animation failed: {e}")
return {"success": False, "error": str(e)}
def _create_hybrid_animation(self, config: AnimationConfig) -> Dict[str, Any]:
"""하이브리드 애니메이션 생성 (LivePortrait + AnimateDiff)"""
try:
# 1단계: LivePortrait로 얼굴 애니메이션 생성
lp_config = AnimationConfig(
input_image_path=config.input_image_path,
output_video_path=str(self.temp_dir / "liveportrait_temp.mp4"),
animation_type="liveportrait",
duration=config.duration,
fps=config.fps
)
lp_result = self._create_liveportrait_animation(lp_config)
if not lp_result["success"]:
return lp_result
# 2단계: AnimateDiff로 배경/전체 움직임 추가
ad_config = AnimationConfig(
input_image_path=lp_result["output_path"],
output_video_path=config.output_video_path,
animation_type="animatediff",
duration=config.duration,
fps=config.fps,
prompt=config.prompt or "smooth camera movement, natural background motion",
enable_background_motion=True
)
ad_result = self._create_animatediff_animation(ad_config)
# 임시 파일 정리
if os.path.exists(lp_config.output_video_path):
os.remove(lp_config.output_video_path)
return ad_result
except Exception as e:
self.logger.error(f"Hybrid animation failed: {e}")
return {"success": False, "error": str(e)}
def _calculate_blink_factor(self, frame_idx: int, total_frames: int) -> float:
"""눈 깜빡임 팩터 계산"""
# 2초마다 깜빡임
blink_period = self.fps * 2
cycle_pos = (frame_idx % blink_period) / blink_period
# 간단한 sine wave 기반 깜빡임
if cycle_pos < 0.1: # 10% 구간에서 깜빡임
return np.sin(cycle_pos * 10 * np.pi) * 0.8
else:
return 0.0
def _generate_driving_motion(self, blink_factor: float) -> Dict[str, Any]:
"""드라이빙 모션 생성"""
return {
"eye_blink": blink_factor,
"head_pose": [0, 0, 0], # [pitch, yaw, roll]
"expression": [0] * 64 # 표정 벡터
}
def _save_video(self, frames: List[np.ndarray], output_path: str, fps: int):
"""비디오 저장"""
if not frames:
raise ValueError("No frames to save")
height, width = frames[0].shape[:2]
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
out = cv2.VideoWriter(output_path, fourcc, fps, (width, height))
for frame in frames:
out.write(frame)
out.release()
self.logger.info(f"Video saved: {output_path}")
def _create_animatediff_workflow(self, config: AnimationConfig) -> Dict[str, Any]:
"""AnimateDiff 워크플로우 생성"""
return {
"1": {
"inputs": {
"ckpt_name": "v1-5-pruned-emaonly.ckpt"
},
"class_type": "CheckpointLoaderSimple"
},
"2": {
"inputs": {
"text": config.prompt or "portrait of a person, natural movement, high quality",
"clip": ["1", 1]
},
"class_type": "CLIPTextEncode"
},
"3": {
"inputs": {
"text": config.negative_prompt or "blurry, low quality, distorted",
"clip": ["1", 1]
},
"class_type": "CLIPTextEncode"
},
"4": {
"inputs": {
"image": config.input_image_path,
},
"class_type": "LoadImage"
},
# AnimateDiff 노드들 추가...
}
def _create_svd_workflow(self, config: AnimationConfig) -> Dict[str, Any]:
"""SVD 워크플로우 생성"""
return {
"1": {
"inputs": {
"model_name": "svd_xt.safetensors"
},
"class_type": "SVDModelLoader"
},
"2": {
"inputs": {
"image": config.input_image_path,
},
"class_type": "LoadImage"
},
"3": {
"inputs": {
"model": ["1", 0],
"image": ["2", 0],
"width": config.resolution[0],
"height": config.resolution[1],
"video_frames": int(config.duration * config.fps),
"motion_bucket_id": 127,
"fps": config.fps,
"augmentation_level": 0.0
},
"class_type": "SVDSampler"
}
}
class ComfyUIClient:
"""ComfyUI 클라이언트"""
def __init__(self, server_url: str):
self.server_url = server_url
def queue_prompt(self, workflow: Dict[str, Any]) -> Dict[str, Any]:
"""워크플로우 실행"""
try:
prompt_id = str(uuid.uuid4())
# 프롬프트 큐에 추가
response = requests.post(
f"{self.server_url}/prompt",
json={"prompt": workflow, "client_id": prompt_id}
)
if response.status_code == 200:
return {"success": True, "prompt_id": prompt_id}
else:
return {"success": False, "error": f"Queue failed: {response.text}"}
except Exception as e:
return {"success": False, "error": str(e)}
# 사용 예제
if __name__ == "__main__":
service = AIAnimationService()
# 설정
config = AnimationConfig(
input_image_path="input/portrait.jpg",
output_video_path="output/animated_portrait.mp4",
animation_type="hybrid", # LivePortrait + AnimateDiff 조합
duration=5.0,
fps=25,
prompt="gentle smile, natural hair movement, soft lighting",
motion_scale=1.2
)
# 애니메이션 생성
result = service.create_animation(config)
if result["success"]:
print(f"Animation created successfully: {result['output_path']}")
else:
print(f"Animation failed: {result['error']}")
2. 웹 API 서버 (flask_api.py)
from flask import Flask, request, jsonify, send_file
from flask_cors import CORS
import os
import uuid
from werkzeug.utils import secure_filename
from ai_animation_service import AIAnimationService, AnimationConfig
import threading
import time
app = Flask(__name__)
CORS(app)
# 설정
UPLOAD_FOLDER = 'uploads'
OUTPUT_FOLDER = 'outputs'
MAX_FILE_SIZE = 16 * 1024 * 1024 # 16MB
os.makedirs(UPLOAD_FOLDER, exist_ok=True)
os.makedirs(OUTPUT_FOLDER, exist_ok=True)
app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER
app.config['MAX_CONTENT_LENGTH'] = MAX_FILE_SIZE
# 서비스 초기화
animation_service = AIAnimationService()
# 작업 상태 추적
job_status = {}
def allowed_file(filename):
"""허용된 파일 확장자 체크"""
ALLOWED_EXTENSIONS = {'png', 'jpg', 'jpeg', 'gif', 'bmp'}
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
@app.route('/api/health', methods=['GET'])
def health_check():
"""서비스 헬스 체크"""
return jsonify({
'status': 'healthy',
'cuda_available': animation_service.device == 'cuda',
'models_loaded': {
'liveportrait': animation_service.liveportrait_pipeline is not None,
'comfyui': animation_service.comfyui_client is not None
}
})
@app.route('/api/animate', methods=['POST'])
def create_animation():
"""애니메이션 생성 API"""
try:
# 파일 업로드 체크
if 'image' not in request.files:
return jsonify({'error': 'No image file provided'}), 400
file = request.files['image']
if file.filename == '':
return jsonify({'error': 'No file selected'}), 400
if not allowed_file(file.filename):
return jsonify({'error': 'Invalid file type'}), 400
# 파일 저장
job_id = str(uuid.uuid4())
filename = secure_filename(f"{job_id}_{file.filename}")
input_path = os.path.join(app.config['UPLOAD_FOLDER'], filename)
file.save(input_path)
# 출력 경로 설정
output_filename = f"{job_id}_animated.mp4"
output_path = os.path.join(OUTPUT_FOLDER, output_filename)
# 요청 파라미터 파싱
animation_type = request.form.get('animation_type', 'liveportrait')
duration = float(request.form.get('duration', 4.0))
fps = int(request.form.get('fps', 25))
motion_scale = float(request.form.get('motion_scale', 1.0))
prompt = request.form.get('prompt', '')
negative_prompt = request.form.get('negative_prompt', '')
# 설정 생성
config = AnimationConfig(
input_image_path=input_path,
output_video_path=output_path,
animation_type=animation_type,
duration=duration,
fps=fps,
motion_scale=motion_scale,
prompt=prompt if prompt else None,
negative_prompt=negative_prompt if negative_prompt else None
)
# 작업 상태 초기화
job_status[job_id] = {
'status': 'processing',
'progress': 0,
'created_at': time.time(),
'config': config.__dict__
}
# 백그라운드에서 애니메이션 생성
thread = threading.Thread(
target=process_animation,
args=(job_id, config)
)
thread.start()
return jsonify({
'job_id': job_id,
'status': 'processing',
'message': 'Animation generation started'
})
except Exception as e:
return jsonify({'error': str(e)}), 500
def process_animation(job_id: str, config: AnimationConfig):
"""백그라운드 애니메이션 처리"""
try:
job_status[job_id]['status'] = 'processing'
job_status[job_id]['progress'] = 10
# 애니메이션 생성
result = animation_service.create_animation(config)
if result['success']:
job_status[job_id] = {
**job_status[job_id],
'status': 'completed',
'progress': 100,
'output_path': result['output_path'],
'result': result
}
else:
job_status[job_id] = {
**job_status[job_id],
'status': 'failed',
'error': result['error']
}
except Exception as e:
job_status[job_id] = {
**job_status[job_id],
'status': 'failed',
'error': str(e)
}
@app.route('/api/status/', methods=['GET'])
def get_job_status(job_id):
"""작업 상태 조회"""
if job_id not in job_status:
return jsonify({'error': 'Job not found'}), 404
status = job_status[job_id].copy()
# 민감한 정보 제거
if 'config' in status:
del status['config']
return jsonify(status)
@app.route('/api/download/', methods=['GET'])
def download_result(job_id):
"""결과 비디오 다운로드"""
if job_id not in job_status:
return jsonify({'error': 'Job not found'}), 404
job = job_status[job_id]
if job['status'] != 'completed':
return jsonify({'error': 'Job not completed'}), 400
if not os.path.exists(job['output_path']):
return jsonify({'error': 'Output file not found'}), 404
return send_file(
job['output_path'],
as_attachment=True,
download_name=f"animated_{job_id}.mp4",
mimetype='video/mp4'
)
@app.route('/api/models', methods=['GET'])
def get_available_models():
"""사용 가능한 모델 목록"""
return jsonify({
'animation_types': [
'liveportrait',
'animatediff',
'svd',
'hybrid'
],
'capabilities': {
'liveportrait': {
'description': '얼굴 표정 애니메이션 (눈 깜빡임, 입술·눈썹 움직임)',
'max_duration': 10.0,
'supports_prompt': False,
'gpu_memory': '4GB+'
},
'animatediff': {
'description': '텍스트 기반 전체 애니메이션',
'max_duration': 20.0,
'supports_prompt': True,
'gpu_memory': '8GB+'
},
'svd': {
'description': '고품질 이미지→비디오 변환',
'max_duration': 8.0,
'supports_prompt': False,
'gpu_memory': '24GB+'
},
'hybrid': {
'description': 'LivePortrait + AnimateDiff 조합',
'max_duration': 15.0,
'supports_prompt': True,
'gpu_memory': '12GB+'
}
}
})
# 정리 작업 (오래된 작업 상태 제거)
def cleanup_old_jobs():
"""오래된 작업 정리"""
current_time = time.time()
expired_jobs = []
for job_id, job in job_status.items():
if current_time - job['created_at'] > 3600: # 1시간 후 정리
expired_jobs.append(job_id)
for job_id in expired_jobs:
# 파일 정리
if 'output_path' in job_status[job_id] and os.path.exists(job_status[job_id]['output_path']):
os.remove(job_status[job_id]['output_path'])
del job_status[job_id]
# 주기적 정리 작업
import atexit
from apscheduler.schedulers.background import BackgroundScheduler
scheduler = BackgroundScheduler()
scheduler.add_job(cleanup_old_jobs, 'interval', minutes=30)
scheduler.start()
atexit.register(lambda: scheduler.shutdown())
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000, debug=False)
3. 웹 프론트엔드 (index.html)
AI 이미지 애니메이션 서비스
인물 사진에 생동감 있는 움직임을 추가하세요
const API_BASE = 'http://localhost:5000/api';
let currentJobId = null;
// DOM 요소
const form = document.getElementById('animationForm');
const imageInput = document.getElementById('imageInput');
const dropZone = document.getElementById('dropZone');
const imagePreview = document.getElementById('imagePreview');
const previewImg = document.getElementById('previewImg');
const animationType = document.getElementById('animationType');
const promptSection = document.getElementById('promptSection');
const duration = document.getElementById('duration');
const durationValue = document.getElementById('durationValue');
const motionScale = document.getElementById('motionScale');
const motionValue = document.getElementById('motionValue');
const generateBtn = document.getElementById('generateBtn');
const progressSection = document.getElementById('progressSection');
const progressBar = document.getElementById('progressBar');
const progressText = document.getElementById('progressText');
const resultSection = document.getElementById('resultSection');
const resultVideo = document.getElementById('resultVideo');
const downloadBtn = document.getElementById('downloadBtn');
// 이벤트 리스너
dropZone.addEventListener('click', () => imageInput.click());
imageInput.addEventListener('change', handleImageSelect);
animationType.addEventListener('change', handleAnimationTypeChange);
duration.addEventListener('input', () => {
durationValue.textContent = duration.value + '초';
});
motionScale.addEventListener('input', () => {
motionValue.textContent = motionScale.value;
});
form.addEventListener('submit', handleSubmit);
// 드래그 앤 드롭
dropZone.addEventListener('dragover', (e) => {
e.preventDefault();
dropZone.classList.add('border-blue-500');
});
dropZone.addEventListener('dragleave', () => {
dropZone.classList.remove('border-blue-500');
});
dropZone.addEventListener('drop', (e) => {
e.preventDefault();
dropZone.classList.remove('border-blue-500');
const files = e.dataTransfer.files;
if (files.length > 0) {
imageInput.files = files;
handleImageSelect();
}
});
function handleImageSelect() {
const file = imageInput.files[0];
if (file) {
const reader = new FileReader();
reader.onload = (e) => {
previewImg.src = e.target.result;
imagePreview.classList.remove('hidden');
dropZone.style.display = 'none';
};
reader.readAsDataURL(file);
}
}
function handleAnimationTypeChange() {
const type = animationType.value;
if (type === 'animatediff' || type === 'hybrid') {
promptSection.classList.remove('hidden');
} else {
promptSection.classList.add('hidden');
}
}
async function handleSubmit(e) {
e.preventDefault();
if (!imageInput.files[0]) {
alert('이미지를 선택해주세요.');
return;
}
const formData = new FormData(form);
generateBtn.disabled = true;
progressSection.classList.remove('hidden');
resultSection.classList.add('hidden');
try {
const response = await fetch(`${API_BASE}/animate`, {
method: 'POST',
body: formData
});
const result = await response.json();
if (result.job_id) {
currentJobId = result.job_id;
pollJobStatus();
} else {
throw new Error(result.error || '알 수 없는 오류가 발생했습니다.');
}
} catch (error) {
alert('오류: ' + error.message);
generateBtn.disabled = false;
progressSection.classList.add('hidden');
}
}
async function pollJobStatus() {
if (!currentJobId) return;
try {
const response = await fetch(`${API_BASE}/status/${currentJobId}`);
const status = await response.json();
progressBar.style.width = status.progress + '%';
progressText.textContent = getStatusText(status.status, status.progress);
if (status.status === 'completed') {
progressSection.classList.add('hidden');
showResult();
generateBtn.disabled = false;
} else if (status.status === 'failed') {
alert('애니메이션 생성 실패: ' + status.error);
progressSection.classList.add('hidden');
generateBtn.disabled = false;
} else {
setTimeout(pollJobStatus, 2000);
}
} catch (error) {
console.error('Status polling error:', error);
setTimeout(pollJobStatus, 5000);
}
}
function getStatusText(status, progress) {
switch (status) {
case 'processing':
if (progress < 20) return '모델 로딩 중...';
if (progress < 50) return '이미지 전처리 중...';
if (progress < 80) return '애니메이션 생성 중...';
return '후처리 중...';
case 'completed':
return '완료!';
case 'failed':
return '실패';
default:
return '대기 중...';
}
}
function showResult() {
const videoUrl = `${API_BASE}/download/${currentJobId}`;
resultVideo.src = videoUrl;
downloadBtn.onclick = () => {
window.open(videoUrl, '_blank');
};
resultSection.classList.remove('hidden');
}
// 초기화
handleAnimationTypeChange();
4. Docker 배포 설정 (Dockerfile)
# CUDA 12.6 기반 PyTorch 이미지 사용
FROM nvidia/cuda:12.6-devel-ubuntu22.04
# 환경 변수 설정
ENV DEBIAN_FRONTEND=noninteractive
ENV PYTHONUNBUFFERED=1
ENV CUDA_HOME=/usr/local/cuda
# 시스템 패키지 설치
RUN apt-get update && apt-get install -y \
python3.10 \
python3.10-dev \
python3-pip \
git \
wget \
curl \
ffmpeg \
libgl1-mesa-glx \
libglib2.0-0 \
libsm6 \
libxext6 \
libxrender-dev \
libgomp1 \
&& rm -rf /var/lib/apt/lists/*
# Python 심볼릭 링크 생성
RUN ln -s /usr/bin/python3.10 /usr/bin/python
# pip 업그레이드
RUN python -m pip install --upgrade pip
# 작업 디렉토리 설정
WORKDIR /app
# Python 의존성 설치
COPY requirements.txt .
RUN pip install -r requirements.txt
# PyTorch CUDA 12.6 설치
RUN pip install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu126
# 애플리케이션 코드 복사
COPY . .
# ComfyUI 설치
RUN git clone https://github.com/comfyanonymous/ComfyUI.git && \
cd ComfyUI && \
pip install -r requirements.txt
# LivePortrait 설치
RUN git clone https://github.com/KwaiVGI/LivePortrait.git && \
cd LivePortrait && \
pip install -r requirements.txt
# ComfyUI 커스텀 노드 설치
RUN cd ComfyUI/custom_nodes && \
git clone https://github.com/kijai/ComfyUI-LivePortraitKJ.git && \
git clone https://github.com/thecooltechguy/ComfyUI-Stable-Video-Diffusion.git
# 추가 의존성 설치
RUN pip install insightface flask flask-cors apscheduler
# 포트 노출
EXPOSE 5000 8188
# 시작 스크립트
COPY start.sh .
RUN chmod +x start.sh
CMD ["./start.sh"]
requirements.txt
torch>=2.0.0
torchvision>=0.15.0
torchaudio>=2.0.0
opencv-python>=4.8.0
numpy>=1.21.0
pillow>=9.0.0
flask>=2.3.0
flask-cors>=4.0.0
requests>=2.31.0
websocket-client>=1.6.0
apscheduler>=3.10.0
insightface>=0.7.3
mediapipe>=0.10.0
gradio>=3.40.0
transformers>=4.30.0
diffusers>=0.20.0
accelerate>=0.20.0
xformers>=0.0.20
safetensors>=0.3.0
start.sh
#!/bin/bash
# ComfyUI 백그라운드 실행
cd /app/ComfyUI
python main.py --listen --port 8188 &
# Flask API 서버 실행
cd /app
python flask_api.py &
# 모든 프로세스 대기
wait
사용 예제 및 결과
LivePortrait 얼굴 애니메이션

특징: 자연스러운 눈 깜빡임, 입술 움직임
처리 시간: ~30초 (RTX 3060 기준)
권장 용도: 인물 초상화, 프로필 이미지
AnimateDiff 프롬프트 트래블

특징: 표정 변화, 자세 변경, 배경 움직임
처리 시간: ~2-5분 (설정에 따라)
권장 용도: 창작 콘텐츠, 스토리텔링
API 사용 예제
# Python 클라이언트 예제
import requests
# 이미지 업로드 및 애니메이션 생성
files = {'image': open('portrait.jpg', 'rb')}
data = {
'animation_type': 'hybrid',
'duration': 5.0,
'fps': 25,
'motion_scale': 1.2,
'prompt': 'gentle smile, natural hair movement, soft lighting'
}
response = requests.post('http://localhost:5000/api/animate', files=files, data=data)
job_id = response.json()['job_id']
# 작업 상태 확인
status_response = requests.get(f'http://localhost:5000/api/status/{job_id}')
print(status_response.json())
# 완료 후 결과 다운로드
if status_response.json()['status'] == 'completed':
video_response = requests.get(f'http://localhost:5000/api/download/{job_id}')
with open('result.mp4', 'wb') as f:
f.write(video_response.content)
문제 해결 및 최적화
CUDA 호환성 문제
증상: "CUDA out of memory" 또는 "CUDA version mismatch"
해결책:
- CUDA 12.6 사용 권장 (12.7 대신)
- 배치 크기 및 해상도 조정
- PyTorch nightly 빌드 사용: pip install --pre torch --index-url https://download.pytorch.org/whl/nightly/cu126
메모리 최적화
VRAM 사용량 최적화:
- LivePortrait: 4-6GB VRAM
- AnimateDiff: 8-12GB VRAM
- Stable Video Diffusion: 16-24GB VRAM (XT 버전 권장)
- 하이브리드 모드: 12-16GB VRAM
성능 최적화 팁
- 해상도 조정: 512×512 권장 (고해상도는 VRAM 소모 증가)
- 지속 시간 제한: 5-10초 권장 (긴 영상은 처리 시간 증가)
- 모델 경량화: LoRA, 양자화 모델 활용
- 배치 처리: 여러 이미지 동시 처리로 효율성 증대
권장 설정
초보자 설정:
- LivePortrait 단독 사용
- 해상도: 512×512
- 지속시간: 3-5초
- FPS: 25
고급 설정:
- 하이브리드 모드
- 해상도: 768×768
- 지속시간: 5-10초
- 프롬프트 트래블 활용
마무리 및 다음 단계
완성된 기능
- Windows 11 + CUDA 12.7 환경 구성
- LivePortrait 얼굴 애니메이션
- AnimateDiff 텍스트 기반 애니메이션
- Stable Video Diffusion 이미지→비디오
- 웹 API 및 프론트엔드 인터페이스
확장 가능한 기능
- 실시간 웹캠 애니메이션
- 배치 처리 시스템
- 클라우드 배포 (AWS/GCP)
- 사용자 인증 및 결제 시스템
- 모바일 앱 연동
이 가이드를 통해 최신 AI 기술을 활용한 이미지 애니메이션 서비스를 성공적으로 구축하실 수 있습니다.
지속적인 모델 업데이트와 성능 최적화를 통해 더욱 발전된 서비스를 만들어보세요!
참고 자료 및 출처
주요 프로젝트
- • LivePortrait GitHub - 얼굴 애니메이션
- • AnimateDiff WebUI - 텍스트 기반 애니메이션
- • ComfyUI SVD - 이미지→비디오
- • ComfyUI LivePortrait - ComfyUI 노드
설치 및 환경 구성
튜토리얼 및 가이드
연구 논문
'AI' 카테고리의 다른 글
| Wan 2.1 Free: Open-Source AI Video Generator"**라는 이름의 공식 오픈소스 프로젝트는 GitHub (0) | 2025.06.26 |
|---|---|
| 환경 설정 및 설치 가이드 (Environment Setup and Installation Guide) (0) | 2025.06.26 |
| 이미지를 자연스러운 동영상으로 변환하는 서비스를 위한 가이드와 소스코드 (0) | 2025.06.26 |
| 이미지를 동영사으로 만드는 오픈 소스 학습 모델 다운로드 받을 수 있는 곳 (0) | 2025.06.26 |
| FOMM과 유사하거나 관련 있는 모델 및 기술 분야 (1) | 2025.06.26 |